






Este informe explica por qué los chips neuromórficos están ganando terreno en IA: reducen consumo y latencia al procesar por eventos, rompiendo con el modelo Von Neumann. Resume conceptos clave, hardware real como Loihi 2, TrueNorth y Akida, y su utilidad en edge computing.
Autor: Alejandro Castillo
Qué son los chips neuromórficos y por qué importan
Los chips neuromórficos surgen cuando el movimiento de datos entre memoria y cómputo se vuelve más costoso que la operación matemática. En vez de correr a ritmo de reloj y de forma continua, activan solo las regiones necesarias cuando ocurre un evento, reduciendo actividad ociosa, latencia y temperatura. No imitan la biología al detalle, adoptan principios físicos útiles como proximidad entre almacenamiento y procesamiento y activación esporádica.
Esta manera de trabajar rompe con Von Neumann porque minimiza traslados entre bloques y asocia el gasto de energía con la actividad real del entorno. La pieza algorítmica que calza con este silicio son las spiking neural networks: codifican información en picos y en el tiempo entre ellos, de modo que el sistema permanece inactivo hasta que hay cambios.
El Informe distingue dos modos de uso: aprendizaje fuera del chip, con modelos entrenados y luego desplegados, y ajustes in-chip más modestos según eventos, aclarando que no todo neuromórfico “aprende” en ejecución.
En las páginas 5 a 7 se ilustra cómo el reloj clásico impone consumo base y cómo la memoria local distribuida acorta recorridos internos; el diagrama de página 6 muestra la separación tradicional CPU-memoria y su costo en tráfico.
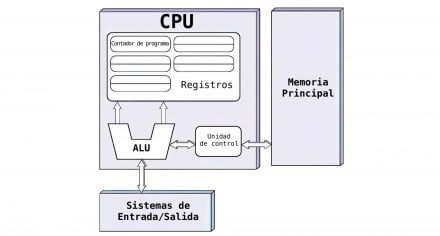
En la arquitectura clásica (Von Neumann), el cálculo y la memoria están en bloques separados: la CPU concentra el control y el cálculo, mientras que la memoria principal permanece separada. Los datos deben trasladarse continuamente entre ambos bloques para cada operación, lo que introduce latencia y un costo energético creciente a medida que aumenta la complejidad del procesamiento.
Ecosistema actual, hardware real y métricas adecuadas
El panorama combina plataformas académicas abiertas para explorar arquitecturas con diseños industriales pensados para operar de forma estable y producible.
Entre los referentes aparecen Loihi 2 de Intel, acompañado por el framework Lava para programar procesos por eventos. TrueNorth de IBM, digital y de muy bajo consumo, con un millón de neuronas y 256 millones de sinapsis, que no aprende en uso. Y Akida de BrainChip, orientado a dispositivos del borde, capaz de ejecutar redes por eventos y redes convencionales con gasto reducido.
También se citan soluciones que integran sensado por eventos y procesamiento en el mismo encapsulado, como Speck de SynSense y la familia DYNAP-CNN para visión.
El documento remarca la variabilidad física y el ruido como rasgos a tolerar, sobre todo en diseños analógico-digitales mixtos, y cómo esa variación no invalida patrones globales.
Para evaluarlos, las métricas de cómputo denso no sirven, se propone medir energía por evento, latencia evento-respuesta, energía por decisión, densidad de neuronas y sinapsis por mm² y consumo en reposo.
La comparación justa con GPU, NPU y MCU se centra en ámbitos de uso: las GPU y NPU sobresalen en cómputo sostenido y paralelo, mientras el neuromórfico brilla cuando la información es irregular y la reacción debe ser inmediata.

Loihi 2 es un chip neuromórfico creado por Intel para investigación. No está pensado para ser un procesador “potente” en el sentido tradicional, sino como una herramienta para experimentar con una forma distinta de trabajo. Se usa en universidades y laboratorios para entender cómo pueden aprender y coordinarse estos chips cuando trabajan juntos, y qué ventajas y límites aparecen al intentar que el aprendizaje ocurra directamente dentro del propio hardware.
Edge computing, interconexión y límites actuales
En el borde, donde la energía es escasa y la respuesta debe ser en tiempo real, el procesamiento por eventos encaja de forma natural: el chip permanece en bajo consumo y se activa solo ante estímulos, lo que mejora autonomía y fiabilidad térmica.
El texto explica que en sistemas sensoriales y reactivos el propio chip puede cerrar el ciclo percepción-decisión-acción sin derivar cada paso a un host, acortando la ruta crítica. Para escalar más allá de un circuito, los eventos deben viajar entre chips sin un reloj global.
El estándar AER (Address-Event Representation), descrito en la sección de interconexión, empaqueta quién se activó y cuándo, enviando solo lo necesario. El diagrama de la página 20 resume esta idea y la página 21 aborda ruteo y coherencia temporal sin sacrificar la naturaleza asincrónica.
Persisten límites técnicos y de adopción: dificultad para mantener uniformidad al escalar densidad, tareas que requieren precisión numérica continua donde un esquema por eventos rinde menos, y fricciones industriales por falta de estándares y herramientas maduras. Aun así, el camino de evolución más claro es integrarlos en SoC híbridos junto a CPU, GPU, NPU y microcontroladores, ubicando al neuromórfico como núcleo eficiente para IA de baja latencia, visión por eventos, robótica ligera y dispositivos siempre encendidos.

La mayor parte del tiempo, el chip permanece en un estado de bajo consumo y se activa solo ante cambios del entorno. Esta dinámica reduce el desgaste térmico y permite sostener sistemas autónomos sin comprometer su capacidad de reacción.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
BATERIAS PARA NOTEBOOKS
Guía práctica y actualizada para diagnosticar, reemplazar y alargar la vida útil de las baterías de notebook. Explica tipos de celdas, señales de desgaste, pasos de sustitución, calibración, riesgos y lo que viene en 2025–2028.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!





