Este informe enseña, con ejemplos claros en PyTorch, cómo funcionan y se entrenan las redes neuronales convolucionales para clasificación de imágenes, desde los bloques básicos hasta transfer learning y fine-tuning con modelos modernos listos para producción.
Autor: Víctor Ojeda
Fundamentos de CNN y flujo de datos
La publicación explica la arquitectura típica de una CNN y el recorrido de la información desde la imagen de entrada hasta la predicción de clases. Se detalla el papel de las capas convolucionales, donde los kernels recorren la imagen para generar mapas de características capaces de detectar bordes, texturas y formas.
El diagrama de la página 3 muestra la jerarquía de patrones que la red aprende, pasando de rasgos simples a objetos completos. El stride controla el desplazamiento del filtro y la resolución de los mapas, y el max pooling compacta la información reteniendo activaciones de mayor intensidad, lo que robustece la detección aunque cambie la posición del objeto.
ReLU aporta no linealidad al anular activaciones negativas, estabiliza la propagación y ayuda a depurar los mapas, como se visualiza en las páginas 5 a 7. Tras el aplanado, las capas totalmente conectadas combinan la información global y Softmax traduce las puntuaciones en probabilidades normalizadas, como se esquematiza en la página 10.
Se repasa además la evolución de arquitecturas, de LeNet-5 a MobileNet, como contexto de la madurez alcanzada por la visión por computadora. En aplicaciones del mundo real, el texto presenta casos de control de accesos y videovigilancia donde una CNN autoriza, alerta o registra eventos en tiempo real, reduciendo tiempos y carga operativa (páginas 20 y 21).
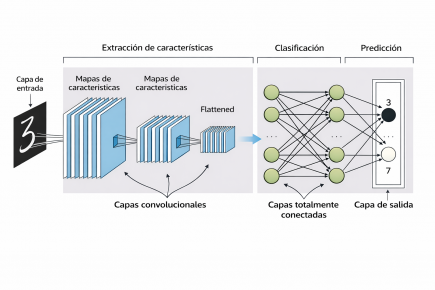
Esquema general de una CNN, que ilustra las etapas de extracción de características, clasifi cación y predicción.
Implementación desde cero con PyTorch
La guía acompaña paso a paso la creación de una CNN para Fashion-MNIST, un dataset de 10 categorías de indumentaria en 28×28 grises. Se sugiere trabajar en un entorno virtual, instalar dependencias y usar DataLoaders para hacer más eficientes el entrenamiento por lotes.
La clase SimpleCNN incorpora dos convoluciones con ReLU y max pooling, y dos capas densas hasta 10 salidas. El forward deja explícito el flujo desde la extracción de rasgos hasta las puntuaciones finales (páginas 14 y 15).
El entrenamiento usa CrossEntropyLoss y Adam, con ciclos de propagación, retropropagación y actualización de pesos a lo largo de épocas, y luego evalúa precisión en test con torch.no_grad() para medir la capacidad de generalización (páginas 16 a 18).
Para análisis cualitativo, se incluye un script que grafica predicciones, etiqueta real y probabilidad de cada imagen, una práctica valiosa para detectar errores de clase y calibrar confianza del modelo.
La página 19 muestra ejemplos de salida con aciertos y sus porcentajes. Esta sección es útil para quien busca una base sólida en clasificación de imágenes con código claro, reproducible y listo para adaptar a otros datasets.
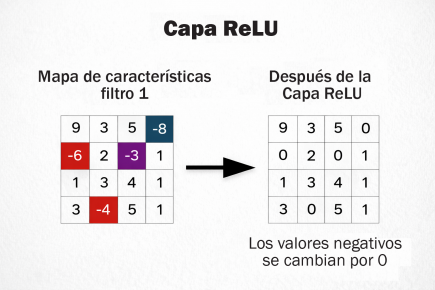
Visualización de ReLU aplicada a un mapa de características.
Modelos preentrenados, transfer learning y fine-tuning
El Informe enseña a reutilizar pesos aprendidos en grandes corpus como ImageNet para acelerar proyectos con menos datos y menor costo computacional. Primero, se ilustra la inferencia directa con ResNet50 en modo evaluación: se normaliza y recorta una imagen a 224×224, se obtiene el índice de clase y se mapea a la etiqueta de ImageNet.
El ejemplo clasifica un pato macho (“drake”) y demuestra el pipeline completo, desde la carga del modelo hasta la obtención de la categoría final (páginas 21 a 24). Luego, el transfer learning congela el backbone convolucional de ResNet50 y reemplaza la capa final para un problema de tres especies (perros, gatos y pandas), logrando buenos resultados con poco entrenamiento cuando el dominio visual es similar al original
La figura de la página 25 resume el proceso y la página 29 exhibe una predicción correcta con alta confianza. Para escenarios con patrones más finos o distintos a ImageNet, se aplica fine-tuning selectivo con MobileNetV3-Small: se congela casi toda la red, se descongela el último bloque de features y el clasificador, y se reentrena sobre distintas especies de monos, donde las diferencias son sutiles y requieren ajustar representaciones de alto nivel.
La secuencia de páginas 31 a 35 muestra el código y un ejemplo de inferencia exitosa. En las tendencias, el documento subraya la ejecución en el edge para bajar latencia y proteger privacidad, y la expansión de tareas hacia detección, segmentación y análisis temporal en video, consolidando a las CNN como pilar de sistemas inteligentes escalables y precisos para visión por computadora (página 36).
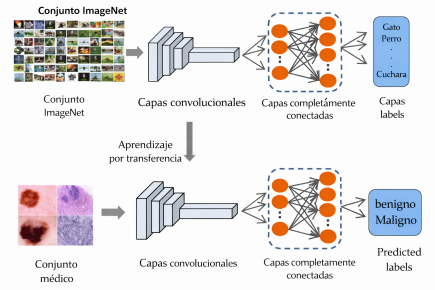
Diagrama del uso de transfer learning en una red convolucional, aplicado a la clasifi cación de imágenes médicas.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
PRESENTACIONES CON IA
El Informe explica cómo crear presentaciones con IA: desde el salto del diseño manual al asistido, hasta qué plataformas convienen según el caso, con pasos prácticos, ventajas, límites y riesgos de privacidad y dependencia. Incluye ejemplos con Gamma, Beautiful.ai, Pitch, Kimi, Copilot, Gemini, Plus AI y Canva.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!