





La popularidad de los grandes modelos de lenguaje despertó curiosidad sobre los mecanismos internos que les permiten conversar, traducir y programar. Este artículo detalla, con lenguaje claro y ejemplos cotidianos, los pasos que siguen para transformar texto en predicciones que parecen propias de un diálogo humano.
Autor: Claudio Peña
De los tokens a los embeddings
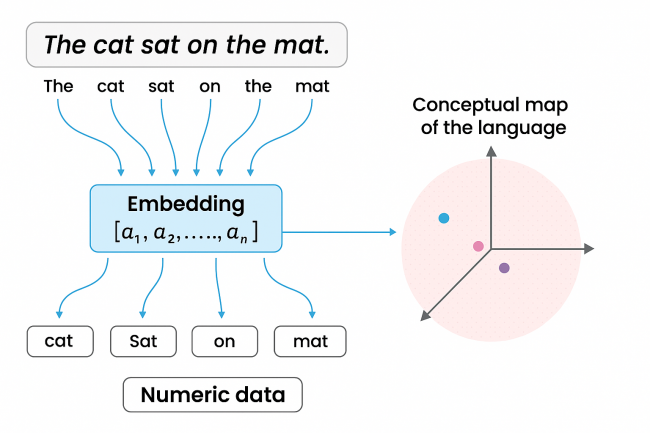
Para una computadora la palabra completa es demasiado voluminosa. La IA moderna parte cualquier frase en tokens —fragmentos que pueden ser sílabas, caracteres o símbolos— mediante algoritmos como Byte Pair Encoding.
Cada token luego se traduce en un identificador numérico y se envía a la capa de embeddings, donde se convierte en un vector dentro de un espacio multidimensional.
En ese mapa los términos con sentidos parecidos quedan cerca, por ejemplo “perro” y “gato”, mientras que ideas alejadas, como “piedra”, se ubican a distancia. Las coordenadas no se asignan a dedo: se entrenan junto al resto de la red para capturar usos, estilos y matices del idioma.
Gracias a esto, un modelo de lenguaje de gran escala (LLM) puede inferir que “autos” está emparentado con “auto” o entender neologismos jamás vistos, porque los tokens nuevos se combinan con piezas ya aprendidas. La tokenización, por lo tanto, reduce complejidad, permite generalizar entre idiomas y facilita que la inteligencia artificial procese documentos de extensión variable sin perder ritmo.
Trabajar con tokens ofrece muchas ventajas. En primer lugar, permite procesar textos de longitud variable sin depender del idioma o de la forma escrita.
Transformers y la atención contextual
El salto decisivo llegó en 2017 con el paper «Attention Is All You Need», donde Google presentó la arquitectura Transformer. A diferencia de las redes recurrentes que analizaban el texto de izquierda a derecha y olvidaban detalles lejanos, el Transformer examina todas las palabras en paralelo mediante un mecanismo de atención auto-regulada.
Cada token genera una consulta (Query), una clave (Key) y un valor (Value) que se cruzan para calcular qué otros fragmentos aportan información útil. Así el modelo sabe que en «El perro que corría ladró» la acción corresponde al animal, no al parque.
Esta mirada global permite capturar dependencias largas y sostener diálogos coherentes, pero está limitada por la ventana de contexto: cierto número de tokens —hoy miles— que caben en memoria simultáneamente. Cuando ese umbral se supera, la IA debe recortar o resumir contenido.
Esa capacidad de prestar atención selectiva, combinada con capas feed-forward muy profundas y millones de parámetros, habilitó LLM populares como ChatGPT, Claude o Gemini y disparó una nueva ola de IA generativa aplicada al procesamiento de lenguaje natural.
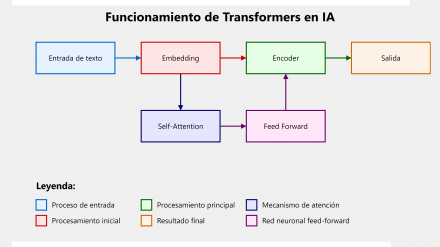
Diagrama simplificado del funcionamiento de los Transformers en inteligencia artificial.
Aprendizaje, generación y desafíos vigentes
Para convertirse en asistentes útiles, los modelos se entrenan con corpus gigantescos mediante aprendizaje supervisado y refuerzo humano.
Cada vez que intentan predecir la palabra siguiente, una función de pérdida mide el error; luego la retropropagación ajusta millones de pesos y sesgos buscando un punto mínimo en la colina del gradiente.
Tras miles de ciclos la red domina patrones morfológicos, sintácticos y semánticos, y al generar texto avanza token a token aplicando técnicas de muestreo como temperatura, top-k o top-p para equilibrar creatividad y precisión.
Con ventanas contextuales ampliadas, algunos sistemas mantienen una memoria temporal de cientos de páginas, suman cadenas de pensamiento para explicar pasos intermedios y se conectan a herramientas externas —calculadoras, bases de datos, navegadores— que reducen alucinaciones y amplían cobertura.
No obstante, persisten límites: sesgos heredados de los datos, invención de contenidos cuando la estadística falla y costos energéticos que crecen con la popularidad del servicio.
Comprender estos retos resulta clave para emplear la inteligencia artificial de forma responsable y potenciar su aporte en la educación, la salud, la industria creativa y la investigación científica.

Algunos modelos ya empezaron a incorporar formas de memoria persistente, que guardan ciertos datos más allá de una sesión, pero todavía es un campo en desarrollo.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
BASES DE LA IA 2.0
Este informe explora las bases arquitectónicas, técnicas y sociales de la inteligencia artificial moderna, abordando sus métodos de entrenamiento, criterios de evaluación, infraestructura tecnológica y desafíos éticos en su implementación global.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!





