





El Informe explica cómo la inteligencia artificial en el borde (Edge AI) pasó de promesa a infraestructura clave. Describe su base técnica, compara con la nube, detalla hardware y modelos optimizados, y analiza beneficios, riesgos, normativas y aplicaciones con impacto industrial, sanitario y urbano.
Autor: Elisa Belmar
Fundamentos y arquitectura de Edge AI
Edge AI traslada la inferencia al lugar donde nacen los datos, reduciendo latencia y preservando privacidad frente al cloud. Un dispositivo de borde combina captura, cómputo y conectividad en un mismo nodo, basado en SoC con CPU, GPU, NPU y, según el caso, DSP, MCU o FPGA.
Esta integración permite procesar video, audio y señales de sensores en tiempo real sin depender del ida y vuelta con servidores remotos. La comparación con la computación en la nube queda clara: la nube conserva el entrenamiento, el orquestado y el almacenamiento de largo plazo; el borde responde en milisegundos con inferencia local y solo sincroniza resúmenes cuando hace falta.
En hardware, se destacan LPDDR como memoria principal, eMMC o UFS para modelos y registros, enlaces Ethernet, Wi-Fi y Bluetooth, y buses I²C o SPI para sensores; MIPI CSI facilita cámaras con baja sobrecarga.
En despliegues masivos, gateways agregan flujos, validan integridad y exponen APIs estables, priorizando robustez térmica (TDP adecuado), expansión vía PCIe y seguridad con secure boot, TPM y enclaves. El SoC es el corazón: coordina recursos, gobierna sensores y puentea el mundo físico con la red digital, optimizando cada watt y cada milisegundo para sostener autonomía operativa incluso con conectividad errática.
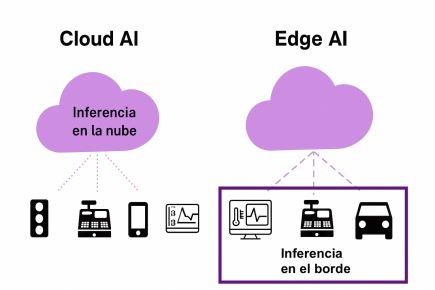
Comparación entre Cloud AI y Edge AI. En el modelo tradicional basado en la nube, la inferencia ocurre en servidores remotos, lo que exige enviar todos los datos desde los dispositivos hacia la nube. En cambio, con Edge AI, el procesamiento se realiza localmente en cada dispositivo, reduciendo la latencia, mejorando la privacidad y permitiendo respuestas inmediatas en entornos como salud, movilidad o comercio.
Modelos, benchmarks y optimización
La ejecución en el borde exige modelos livianos y eficientes. Técnicas como cuantización a enteros de 8 bits, poda de conexiones de bajo impacto, destilación de conocimiento y compresión estructural reducen tamaño y costo de cómputo con pérdidas de precisión bien acotadas.
Suites como MLPerf Tiny y Edge MLBench miden más que throughput: consideran energía por inferencia, tiempo de arranque, huella de memoria y comportamiento térmico, lo que permite detectar cuellos de botella y ajustar el balance entre precisión, latencia y consumo.
MobileNet ejemplifica el diseño para dispositivos móviles mediante depthwise separable convolutions, logrando buenas tasas de acierto con baja latencia en smartphones y cámaras inteligentes; TinyML lleva redes a microcontroladores con menos de 1 MB, sin sistema operativo, con variantes como TensorFlow Lite Micro.
Estas opciones habilitan pipelines de visión, voz y sensores en equipos compactos, pero marcan límites para LLMs y modelos multimodales de gran porte en el borde. La lectura de benchmarks debe ser contextual: un pequeño aumento de precisión puede no justificar más gasto energético, y en robótica o conducción, priorizar latencia mínima suele ser decisivo para la seguridad.
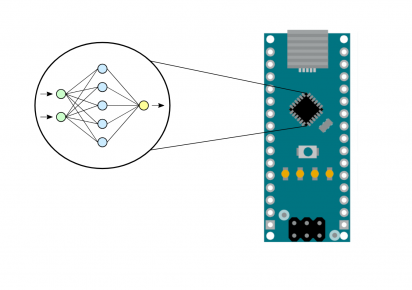
TinyML permite ejecutar redes neuronales en microcontroladores de bajo consumo, como los integrados en placas Arduino. Esta tecnología lleva la inferencia de modelos de IA directamente al hardware embebido, sin necesidad de conexión constante a la nube.
Aplicaciones, riesgos y marco normativo
Los beneficios técnicos se traducen en casos de uso de alto impacto: movilidad autónoma con detección local de peatones y obstáculos; videovigilancia con análisis en cámara; industria con mantenimiento predictivo a partir de vibración y temperatura; salud digital con monitoreo biométrico en tiempo real; servicios públicos con iluminación y residuos inteligentes.
La continuidad sin conexión sostenida y la menor exposición de datos refuerzan la privacidad y la resiliencia. El aprendizaje federado permite entrenar sin centralizar datos: cada nodo actualiza parámetros locales y un servidor agrega gradientes para un modelo global, reduciendo tráfico y respetando restricciones legales.
La convergencia con IoT satelital extiende la inferencia a zonas remotas mediante LEO y procesamiento en órbita, habilitando alertas agrícolas, ambientales o de infraestructura con menor costo de transmisión.
Persisten límites por potencia, memoria y energía, junto con el desafío de mantener y orquestar múltiples versiones de modelos en campo. La superficie de ataque incluye robo de modelo, membership inference, firmware vulnerable, accesos remotos inseguros y ataques adversariales físicos; mitigaciones como cifrado, verificación de integridad, OTA firmadas y enclaves son claves en nodos expuestos.
El cumplimiento regula el diseño: GDPR y el AI Act en la UE exigen trazabilidad, explicabilidad y control de datos; en EE. UU., FDA y FCC impactan en dispositivos médicos y radiofrecuencia; estándares ISO/IEEE avanzan en interoperabilidad, auditabilidad y robustez.
Las líneas de investigación apuntan a arquitecturas miniaturizadas mediante búsqueda automática adaptada al borde, privacidad diferencial aplicada en dispositivos y autonomía colaborativa entre nodos para decidir y reajustarse sin servidor central, dentro de arquitecturas híbridas que combinan nube y borde según la tarea.

En los sistemas de conducción automatizada, el Edge AI permite procesar datos críticos directamente a bordo del vehículo. Esto reduce la latencia en la toma de decisiones y evita depender de la conectividad con la nube para tareas como el reconocimiento de objetos, la detección de obstáculos y la navegación autónoma.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
IA OPTICA SUPERCOMPUTACION CON FIBRA DE VIDRIO
Este informe explica cómo la IA óptica y el cómputo fotónico buscan superar los límites del silicio, trasladando parte del procesamiento a la luz para acelerar la supercomputación y reducir consumo energético, con aplicaciones en centros de datos, ciencia y modelos de lenguaje, y retos industriales por resolver.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!





