La inteligencia artificial local ya dejó de ser una rareza técnica y se perfila como una opción concreta para trabajar, crear y automatizar sin depender de Internet. El informe recorre qué puede hacerse hoy con IA 100 % offline, qué hardware conviene y qué herramientas vuelven posible ese uso cotidiano.
Auto: Claudio Bottini
Por qué crece la IA sin nube
El informe explica que el regreso del procesamiento local nace de una combinación de modelos abiertos más livianos, computadoras más potentes y software mucho más simple de usar.
Frente al esquema clásico de enviar datos a servidores remotos, la IA local permite mantener textos, audios, imágenes y documentos dentro del propio equipo. Eso mejora la privacidad, reduce la latencia y evita costos variables por token o suscripción.
También aporta continuidad de trabajo cuando falla la conexión o cuando se necesita operar en viajes, zonas remotas o entornos con restricciones de seguridad.
En ese marco, el Informe muestra que la IA offline no busca reemplazar a los modelos más grandes de la nube en todos los casos, sino resolver tareas concretas con rapidez y control.
Redacción, edición, resumen de documentos, análisis de archivos, asistentes privados, apoyo al estudio y automatización básica aparecen como usos ya maduros.
Para ámbitos como salud, educación, derecho, periodismo o empresas, que los datos no salgan del dispositivo pasa a ser un punto muy valioso.

Con IA local, el modelo vive en el dispositivo. Los datos no salen. No hay subida, no hay terceros, no hay intermediarios. Para muchos contextos —educativos, médicos, legales, periodísticos o empresariales— esta diferencia es fundamental.
Hardware, modelos y plataformas para usarla
El texto marca que la viabilidad de esta etapa depende mucho del nuevo hardware. La NPU gana lugar como coprocesador dedicado a la inferencia, junto con las CPU y GPU, y aparecen equipos pensados para sostener modelos pequeños y medianos con bajo consumo.
Se mencionan avances de Qualcomm con Snapdragon X2 Elite y de AMD con Ryzen AI 300, en una carrera donde importan los TOPS (Tera Operations Per Second), el ancho de banda de memoria y la eficiencia energética.
En cuanto a modelos, el informe destaca que no siempre conviene elegir el más grande. Muchas veces un modelo chico, cuantizado o especializado rinde mejor para una tarea puntual y puede ejecutarse en notebooks comunes.
Entre los nombres citados aparecen Llama 4, Gemma 3, Qwen 3, DeepSeek-R1 y Phi-3, con buen desempeño en escritura, razonamiento, programación y análisis de documentos. También se explica que el código abierto permite ajustar modelos con datos propios o combinarlos con bases documentales locales mediante RAG, para responder con un contexto actualizado sin reentrenarlos cada vez.
A nivel de software, Ollama aparece como la puerta de entrada más amigable para correr modelos locales en Windows, macOS y Linux. Su valor está en simplificar la descarga, gestión y ejecución desde la línea de comandos o la interfaz gráfica.
Junto a Ollama, el Informe menciona LM Studio, GPT4All, Open WebUI y AnythingLLM como opciones útiles para explorar modelos, montar chats privados, consultar documentos y ofrecer experiencias parecidas a servicios en la nube, pero dentro de la propia máquina.

Los fabricantes de procesadores han entendido que la inferencia neuronal no es una carga de trabajo más, sino una de las cargas dominantes del futuro inmediato.
Más allá del texto: imágenes, audio y uso práctico
El recorrido no se limita a los LLM. Para generación visual, ComfyUI se presenta como una herramienta potente para crear imágenes y video de forma local con modelos abiertos como Stable Diffusion, Flux o Wan2.x. Su lógica por nodos permite diseñar flujos creativos reutilizables y trabajar sin límites de uso, más allá de la capacidad del hardware.
El Informe aclara que no hace falta empezar con configuraciones extremas: con resoluciones moderadas y modelos optimizados ya se logran resultados útiles.
En audio, se destaca a Whisper para transcripción local y a Piper para síntesis de voz, dos piezas que abren la puerta a asistentes hablados, accesibilidad, notas de voz, entrevistas y reuniones sin subir archivos a Internet. También se muestra cómo integrar estas herramientas por código para automatizar tareas enteras desde Python.
Por último, el Informe amplía la mirada hacia celulares y equipos de bajo consumo, donde ya corren modelos compactos para consultas simples, clasificación, texto breve y asistencia personal.
Aun con límites de memoria, batería y velocidad, la experiencia ya es funcional. La idea central del texto es que la IA local no busca armar una guerra contra la nube, sino una estrategia híbrida en la que muchas tareas pueden resolverse cerca del dato, con más privacidad, menor demora y mayor autonomía.
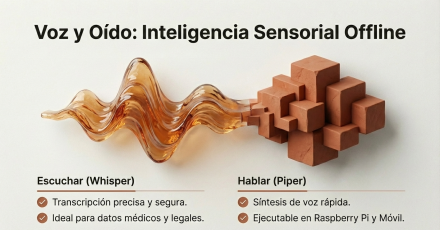
Para el camino inverso —convertir texto en voz— una opción especialmente amigable es Piper, un motor de síntesis de voz local que se destaca por su bajo consumo de recursos y su facilidad de uso. Piper permite generar locuciones, narraciones o lecturas automáticas sin conexión a Internet y sin restricciones de uso. Resulta particularmente interesante para pruebas creativas, accesibilidad o asistentes locales simples, donde no se requiere un nivel de hiperrealismo extremo.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
MOLTBOT (EX-CLAWDBOT) EL CONTROL EN MANOS DE LA IA
La aparición de Moltbot (antes Clawdbot) marca un cambio práctico: la inteligencia artificial deja de limitarse a responder y pasa a ejecutar acciones dentro de un entorno digital real, con efectos concretos sobre archivos, programas y procesos. Ese salto obliga a pensar permisos, límites y responsabilidad de uso.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!