Este informe explica por qué los datos pesan más que el algoritmo cuando un sistema automatizado decide, clasifica o recomienda. La idea principal es simple: sin control sobre la calidad, el origen y el contexto del dato, cualquier resultado puede parecer confiable sin serlo.
Auto: Elisa Belmar
Auditar datos para entender qué decide el sistema
El texto plantea que revisar solo el modelo no alcanza, porque muchas fallas nacen antes, en la información que lo alimenta. Auditar datos no es buscar errores de tipeo ni campos vacíos de manera aislada, sino reconstruir la historia completa del dato: de dónde sale, cómo fue recolectado, qué filtros recibió, qué partes de la realidad deja afuera y para qué uso tiene sentido. Desde esa mirada, la auditoría permite pasar de una confianza ciega a una confianza explicable.
El Informe insiste en que un sistema puede verse ordenado, estable y hasta eficiente, pero seguir decidiendo con datos incompletos, viejos o mal representados. También marca que la calidad no depende solo de que un dato esté prolijo, sino de si sirve para la decisión concreta que se quiere tomar.
Por eso aparecen dimensiones como completitud, coherencia interna, actualidad, precisión y representatividad, que en el gráfico de la página 5 se muestran como piezas de una misma rueda.
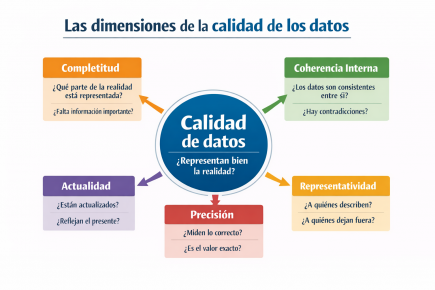
La calidad se define en el uso: las mismas dimensiones cambian de peso según la decisión que el sistema automatiza.
Calidad, sesgos y degradación que no siempre se ven
Uno de los aportes más fuertes del Informe es mostrar que un dato puede estar bien escrito y, aun así, ser inútil o engañoso para cierto contexto. A partir de ahí, desarrolla cómo nacen los sesgos en el muestreo, el etiquetado y la cobertura. Si un sistema aprende sobre una parte de la población, después responderá mejor para ese grupo y peor para el resto.
En las páginas 6 y 7 se explica que las etiquetas también cargan decisiones humanas, culturales y operativas, de modo que el modelo no descubre una verdad neutral, sino que replica criterios previos.
El texto suma otro problema delicado: las verdades heredadas. Cuando se usan bases históricas sin revisión, el sistema puede repetir desigualdades viejas como si fueran datos objetivos del presente. A eso se agrega la degradación silenciosa, desarrollada entre las páginas 11 y 16. Los datos pueden perder vigencia sin que el sistema se rompa de golpe. Todo sigue funcionando y los tableros continúan en verde, pero la realidad ya cambió.
El Informe explica que ahí aparece el drift, que altera relaciones, distribuciones y sentidos sin dar una alarma evidente. Incluso advierte que los dashboards suelen mostrar estabilidad y esconder incertidumbre, lo que crea una falsa sensación de control.

El riesgo aumenta cuando las fuentes externas se consideran “neutrales” por defecto. APIs públicas, datos abiertos o registros compartidos suelen asumirse como confiables, cuando en realidad reflejan intereses, errores o manipulaciones posibles. En estos casos, el problema no es técnico en sentido estricto, sino de confianza mal ubicada.
Estructura, seguridad y regulación para no automatizar a ciegas
En la parte final, el Informe propone una auditoría estructural apoyada en documentación, lineaje y contratos de datos. Documentar no es cumplir con un trámite, sino dejar por escrito qué representa cada campo, qué supuestos se tomaron y qué usos no corresponden.
El lineaje, ilustrado en la página 9, permite seguir el recorrido del dato a través de fuentes, versiones y transformaciones para detectar dónde se introducen errores o pérdidas de contexto. Los contratos de datos, junto con el ejemplo de JSON Schema de la página 10, aparecen como acuerdos técnicos que vuelven verificables expectativas que muchas veces quedan implícitas.
El texto también lleva la discusión al terreno de la seguridad: un sistema puede ser manipulado no solo por un ataque a la infraestructura, sino por datos contaminados, fuentes externas poco confiables o bucles de retroalimentación que refuerzan errores.
En las páginas 17 a 19 suma la presión regulatoria, con el EU AI Act como caso de referencia, y sostiene que auditar datos ya no es solo una buena práctica. Al mismo tiempo, aclara que no hace falta frenar toda la operación para empezar: primero hay que saber qué datos existen, para qué decisiones se usan y qué capas mínimas de control conviene incorporar antes de avanzar.
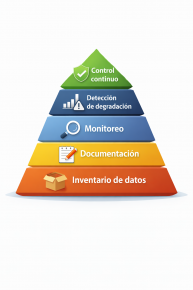
No se trata de hacerlo todo desde el principio, sino de empezar por la base —saber qué datos existen— y avanzar capa por capa sin perder el control.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
GPT-5.3 CODEX GENERACIÓN, MODIFICACIÓN Y VALIDACIÓN
Este informe analiza cómo GPT-5.3 Codex pasa de asistir en la escritura de código a intervenir en tareas completas de desarrollo, con capacidad para leer repositorios, ejecutar acciones y sostener la continuidad técnica dentro de proyectos reales.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!