





Guía práctica para aprender ciencia de datos con Python: instalación ágil, manipulación de datos con pandas, visualización con Matplotlib y modelos básicos de machine learning con scikit-learn, todo aplicado paso a paso y con ejemplos reproducibles en JupyterLab y Anaconda para acelerar proyectos reales.
Autor: Claudio Bottini
Inicio rápido con Python y Anaconda
El material presenta a la ciencia de datos como un medio para transformar información cruda en conocimiento útil, combinando estadística, programación y contexto de negocio.
Python se destaca por su sintaxis sencilla, ecosistema enorme y comunidad activa. Se recomienda usar versiones 3.x modernas y trabajar con Anaconda para obtener un entorno completo con Python, JupyterLab y librerías clave.
Se promueve el uso de entornos virtuales (venv o conda) para aislar dependencias y garantizar reproducibilidad. El texto ofrece comandos concretos para crear y activar entornos, instalar paquetes como pandas, numpy, matplotlib, seaborn, scikit-learn, jupyterlab y openpyxl, además de ydata-profiling para EDA automático.
Se incluye un chequeo inicial que descarga un CSV remoto con pandas, imprime head, info y describe, y resalta buenas prácticas: congelar dependencias con requirements.txt, usar notebooks para experimentar y migrar a scripts cuando el proyecto escale.
Todo el flujo apunta a un setup estable y portable en Windows, Linux o macOS, reduciendo fricciones y facilitando la colaboración.

Como los proyectos de ciencia de datos suelen ejecutarse en momentos puntuales y no requieren un servidor funcionando permanentemente, Anaconda permite activar y desactivar entornos de forma rápida, optimizando recursos y manteniendo la reproducibilidad del trabajo.
Pandas y visualización con Matplotlib
Pandas se presenta con su estructura central, el DataFrame, ideal para cargar, explorar, limpiar y transformar datos tabulares. Se muestran lecturas desde CSV por URL y Excel, y una inspección rápida con shape, columns, head, tail y describe.
Se aborda un problema común: nombres de columnas con espacios o comillas que rompen accesos; la solución es normalizar encabezados con strip y replace, y renombrar a etiquetas más claras en español (Índice, Altura, Peso). Luego se trabaja selección y filtrado por columnas y filas con loc/iloc, además de transformaciones como crear una columna de IMC y detección/gestión de nulos con isnull, dropna y fillna.
Se insiste en verificar tipos y, ante transformaciones grandes, operar sobre copias para evitar pérdidas. La visualización con Matplotlib arranca con líneas, barras, histogramas y dispersión para detectar patrones y valores atípicos.
Se agregan tips útiles para SEO y práctica profesional: títulos y ejes descriptivos, grid para lectura rápida, tamaños personalizados y guardado a archivo con savefig. También se sugiere df.plot(…) como atajo para gráficos rápidos sobre DataFrames ya cargados.
Con esto, la guía empalma EDA visual y numérica para entender la distribución y relaciones entre variables antes de modelar.
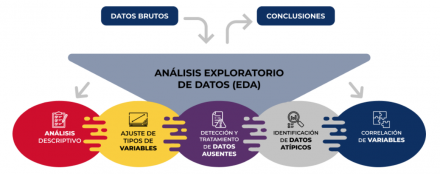
Todas las tareas revisadas forman parte de lo que en el mundo de la ciencia de datos se conoce habitualmente como EDA: Análisis Exploratorio de Datos.
Modelado con scikit-learn y proyecto de elecciones
La sección de machine learning introduce el flujo clásico: preparar features y target, dividir en train/test, elegir modelo, entrenar, predecir y evaluar con métricas. Con el dataset Altura-Peso se entrena una regresión lineal para estimar Peso a partir de Altura y se interpretan coeficiente, intercepto, R² y MSE, aclarando que, si bien la tendencia ayuda, el ajuste depende del conjunto usado.
Para clasificación, se muestra un ejemplo didáctico con árboles de decisión, primero trivial (usar como predictor la misma variable que define la etiqueta, lo que produce precisión perfecta pero sin valor práctico) y luego uno más interesante: predecir si Peso ≥ 150 lb usando Altura, con una precisión inferior pero más realista. Se enseña a visualizar el árbol y a usar predict_proba para obtener probabilidades.
La guía culmina con un caso real de elecciones municipales en formato CSV con separador “;”. Se cargan y limpian columnas, se exploran totales y porcentajes por partido, y se grafican resultados por mesa y por lugar de votación.
Se incluyen técnicas para detectar mesas anómalas mediante promedios, diferencias absolutas y un heatmap de correlaciones entre partidos con seaborn. Se identifican ganadores por mesa con idxmax y se marcan excepciones visualmente, útil para auditoría y control de calidad de datos.
Finalmente, se entrena un árbol de decisión para predecir el partido ganador por mesa usando como predictores los votos de cada fuerza; se evalúa precisión, se visualizan reglas y se muestran predicciones con datos nuevos, incluso con información incompleta, posicionando al modelo como un “laboratorio” para simular escenarios y apoyar decisiones.

La ventaja es que con pocas líneas de código podemos entrenar y evaluar modelos sin ser expertos en estadística.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
PYTHON MAS GEMINI SON TUS ANALISTAS FINACIERO
Guía práctica para crear un asesor financiero personal con Python e IA que automatiza datos, análisis y reportes interactivos usando Gemini, yfinance, pandas y Plotly, todo pensado para una cartera real y procesos reproducibles.
Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!





