






Este informe analiza cómo GPT-5.3 Codex pasa de asistir en la escritura de código a intervenir en tareas completas de desarrollo, con capacidad para leer repositorios, ejecutar acciones y sostener la continuidad técnica dentro de proyectos reales.
Auto: Alejandro Castillo
Codex como agente dentro del desarrollo
El texto plantea que GPT-5.3 Codex ya no debe evaluarse solo por la calidad del código que produce, sino por el tipo de trabajo que puede asumir dentro del ciclo de vida del software. En lugar de limitarse a completar funciones o responder pedidos puntuales, puede revisar dependencias, interpretar relaciones entre módulos y organizar una secuencia de cambios antes de actuar. Esa lógica lo acerca a un agente operativo supervisado, capaz de intervenir con herramientas externas y mantener el hilo entre distintos pasos del proyecto.
La publicación explica que esta diferencia se vuelve visible desde el acceso inicial. En modo nube sirve para analizar archivos y explorar proyectos pequeños, mientras que la versión instalable habilita comandos reales, ejecución de pruebas, cambios coordinados y trabajo con repositorios locales o remotos.
La recomendación es comenzar con un diagnóstico general del repositorio para validar si el sistema comprende arquitectura, dependencias críticas y riesgos técnicos antes de delegar tareas más amplias.
Para trabajar con repositorios locales y ejecutar comandos reales, debes elegir Descargar, según el sistema operativo que estés ejecutando.
Arquitectura, contexto y ejecución sobre repositorios
Uno de los puntos centrales del informe es que Codex trabaja sobre el repositorio como sistema y no sobre fragmentos sueltos. Para eso combina el modelo GPT-5.3 con una capa operativa que organiza el contexto, toca archivos, coordina acciones y conserva la continuidad entre pasos. El Informe destaca que la mejora de la versión 5.3 frente a 5.2 se nota sobre todo en la estabilidad durante tareas largas, en la menor cantidad de fallos intermedios y en una mejor consistencia cuando aparecen resultados inesperados.
También se explica el papel del contexto largo y la compactación. A medida que una sesión avanza, Codex resume lo ya recorrido para no perder capacidad de decisión en repositorios extensos. Esa lectura transversal le permite identificar imports, configuraciones, rutas, pruebas y puntos de acoplamiento antes de modificar nada. Desde ahí puede ejecutar comandos, validar resultados, corregir errores si una prueba falla y sostener cambios complejos que atraviesan varias capas del sistema.
El informe muestra además que esta lógica sirve para refactorizaciones amplias, migraciones de dependencias y reorganización de módulos. En esos casos no alcanza con que una modificación sea correcta en un archivo aislado: debe conservar la coherencia en el proyecto completo y dejar claro por qué se hizo cada cambio.

Mientras el modelo genera texto y código, Codex se encarga de la operación: mantener el estado del trabajo, ejecutar acciones sobre el proyecto y sostener una secuencia de pasos sin perder el contexto.
Rendimiento, comparación con otras herramientas y límites
La publicación dedica varias páginas a medir a Codex con benchmarks orientados a problemas reales. En SWE-Bench Pro, centrado en corregir errores documentados dentro de repositorios existentes, la mejora aparece como moderada. Donde el salto resulta más visible es en Terminal-Bench 2.0 y OSWorld-Verified, pruebas ligadas al uso de consola, archivos y tareas operativas encadenadas.
El mensaje general es que Codex 5.3 sobresale más por su capacidad para actuar y verificar dentro de entornos reales que por escribir código aislado.
Frente a alternativas como GitHub Copilot, Claude Code y Gemini Code Assist, el informe marca una diferencia clara. Copilot sigue muy ligado al IDE y a la asistencia contextual; Claude Code ofrece gran capacidad analítica y contexto extendido, pero no siempre cierra dentro de la misma sesión el ciclo de ejecución y verificación; Gemini prioriza la integración empresarial y servicios cloud. Codex 5.3, en cambio, reúne generación, modificación y validación en una misma dinámica de trabajo.
El texto también subraya que esa mayor autonomía exige controles estrictos. Se mencionan riesgos como prompt injection, exposición de información sensible y generación de vulnerabilidades no detectadas en pruebas básicas. Por eso la supervisión humana sigue siendo indispensable. El desarrollador no desaparece: cambia su lugar en la práctica diaria. Pasa de concentrarse solo en escribir línea por línea a definir objetivos, revisar resultados, integrar acciones paralelas y decidir cómo incorporar los cambios en un sistema vivo.
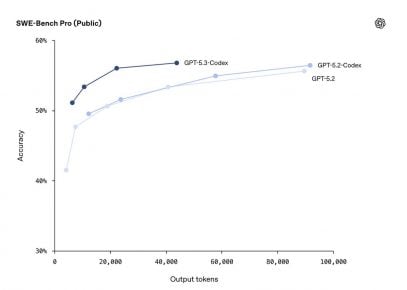
Precisión en SWE-Bench Pro según cantidad de tokens generados. A medida que el modelo produce más salida, GPT-5.3 Codex mantiene mejor rendimiento que 5.2, especialmente en tareas de corrección sobre proyectos reales.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
MOLTBOT (EX-CLAWDBOT) EL CONTROL EN MANOS DE LA IA
La aparición de Moltbot (antes Clawdbot) marca un cambio práctico: la inteligencia artificial deja de limitarse a responder y pasa a ejecutar acciones dentro de un entorno digital real, con efectos concretos sobre archivos, programas y procesos. Ese salto obliga a pensar permisos, límites y responsabilidad de uso.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!





