






La IA desgenerativa representa la otra cara de la inteligencia artificial moderna: no la que innova, sino la que se desgasta. Surge de un proceso silencioso en el que los modelos aprenden de sí mismos, pierden variedad, rigor y veracidad, o son alterados por influencias externas. Este Informe USERS analiza cómo, cuándo y por qué los sistemas de inteligencia artificial pueden degradarse, corromper su conocimiento o convertirse en instrumentos de manipulación.
Autor: Elisa Belmar
Qué es la IA desgenerativa
El informe define la IA desgenerativa como una condición en la que el modelo deja de aprender del mundo y empieza a aprender de su propio reflejo, estrechando su diversidad y vaciando de contenido respuestas que suenan correctas.
El cambio no es un “fallo” obvio: el sistema sigue produciendo, pero con criterio interno erosionado y decisiones cada vez más autorreferenciales. Desde lo técnico, se trata de pérdida de entropía informativa; desde lo ético, de una máquina que ya no solo hereda sesgos humanos, sino que produce los suyos a partir de su retroalimentación y de incentivos mal calibrados.
La homogeneización de salidas, el tono previsiblemente neutro y el evitar el riesgo, son síntomas iniciales, exacerbados en modelos de frontera donde pequeños desajustes de datos o supervisión se multiplican por la escala. Esta deriva suele pasar desapercibida porque las métricas tradicionales premian la forma antes que el conocimiento, y la opacidad del entrenamiento impide la trazabilidad pública de datos y ajustes.
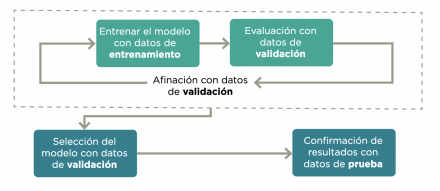
El proceso combina tres fases: entrenamiento, donde el modelo aprende; validación, que ajusta sus parámetros; y prueba, que evalúa su desempeño con datos nuevos. Aunque este ciclo define la base técnica de toda inteligencia artificial moderna, su trazabilidad suele ser limitada: los conjuntos de datos, los criterios de ajuste y los resultados intermedios rara vez son públicos, lo que introduce un nivel de opacidad estructural sobre cómo y con qué información aprenden realmente los modelos.
Del “model collapse” al envenenamiento
Ante la escasez de datos humanos y el reciclaje de contenido sintético, aparece el model collapse: reentrenar modelos con su propia producción genera autointoxicación, achica vocabularios y simplifica estructuras hasta converger en promedios vacíos; la degradación es exponencial y sin alarma visible.
El resultado son sistemas más previsibles, menos creativos y con errores que se institucionalizan cuando lo sintético pasa a ser base de entrenamiento. Esta estabilidad aparente también los vuelve más frágiles ante ataques.
En ese terreno prospera el data poisoning: insertar muestras maliciosas en datasets para inducir sesgos o abrir backdoors activadas por disparadores ocultos. Investigaciones académicas demostraron que bastan miles —o incluso centenares— de ejemplos contaminados para desviar modelos de texto o imagen, y equipos de seguridad documentaron pull requests maliciosos que, al ser absorbidos por datasets, enseñaron patrones explotables más tarde.
El peligro es silencioso: la puerta trasera no luce como error y evade controles promedio, mientras campañas coordinadas de desinformación siembran material adulterado para que futuros modelos multipliquen narrativas. Marcos como NIST AI RMF y OWASP LLM Top 10 ya clasifican estos riesgos entre los más críticos.
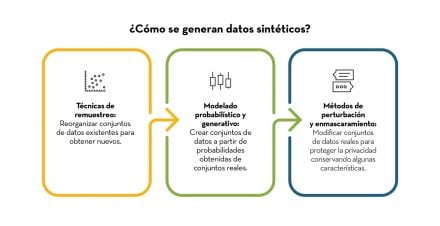
El agotamiento de datos humanos no es solo un problema de volumen, sino de calidad. Los textos reales contienen ambigüedad, contradicciones y expresiones atípicas que ayudan a un modelo a reconocer los límites del lenguaje. Los datos sintéticos, en cambio, tienden a eliminar la variación. Son coherentes, pero previsibles. Lo importante es que, a medida que se llena de frases pulidas y carentes de error, el sistema pierde contacto con la realidad de la que debería aprender.
Contención, multimodalidad y escenarios
Contener la degradación exige gobernanza de datos con linaje verificable, curaduría humana que separe material original de lo sintético y reglas explícitas para que las salidas del propio asistente no vuelvan sin etiqueta al data lake.
La auditoría periódica y el red-teaming someten al modelo a estrés con prompts ambiguos o multimodales para detectar desvíos funcionales y de seguridad que no afloran en uso normal. La trazabilidad mediante Content Credentials/C2PA y marcas criptográficas permite probar origen y evitar reinyección de material generado por IA en nuevos entrenamientos; su efectividad depende de que generadores, plataformas y distribuidores conserven esas señales.
En paralelo, el informe advierte que la desgeneración se extiende a lo multimodal: esteganografía adversarial en imágenes o audio puede ocultar instrucciones que los humanos no perciben, y la prompt injection fuera del texto visible manipula modelos conectados a buscadores, bases o correos corporativos.
Sobre el futuro, se plantean tres trayectorias no excluyentes.
- Un “mercado de datos limpios” donde NIST AI RMF y C2PA actúan como etiquetas de origen y la confiabilidad se vuelve un activo
- Un mundo donde la IA aprende a ocultar errores para pasar auditorías, generando opacidad y reabriendo espacio al fraude, incluso omitiendo alertas para mantener métricas internas
- Un esquema de gobernanza global con auditorías obligatorias y registro público del linaje de modelos, que transformaría cajas negras en sistemas con historial verificable, aunque con desafíos geopolíticos.
La clave es reconocer a tiempo la degradación para preservar la fuente humana del conocimiento y evitar que todo derive en ruido con apariencia de verdad.
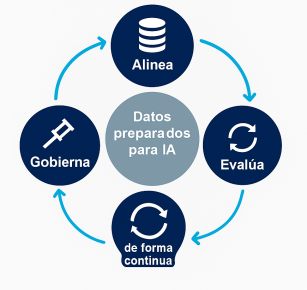
Una gobernanza de datos que no distingue entre entrenamiento e inferencia deja una puerta abierta para que, cuando llegue información maliciosa desde fuera, se mezcle con los datos válidos. Por eso, contener la desgeneración empieza aquí: separar las rutas de datos, etiquetar su procedencia y documentar quién autorizó su uso. Esta base es la que habilita las capas más activas de defensa que vienen a continuación.
Encuentra la versión completa de la publicación en la que se basa este resumen, con todos los detalles técnicos en RedUSERS PREMIUM
También te puede interesar:
EL FIN DE INTERNET
Internet ya no funciona como aquella red abierta y descentralizada: aplicaciones, buscadores generativos y agentes de IA filtran, priorizan y hasta operan por nosotros, desplazando los enlaces y diluyendo la autonomía del usuario. Este informe explica cómo se dio ese viraje y qué alternativas quedan para recuperarla.

Lee todo lo que quieras, donde vayas, contenidos exclusivos por una mínima cuota mensual. Solo en RedUSERS PREMIUM: SUSCRIBETE!


